Reading in files from various formats (.xls, .xlsx, .csv, .txt, .sps, .xport)
Summarizing Data using dplyr (Toolbox of data cleaning function)
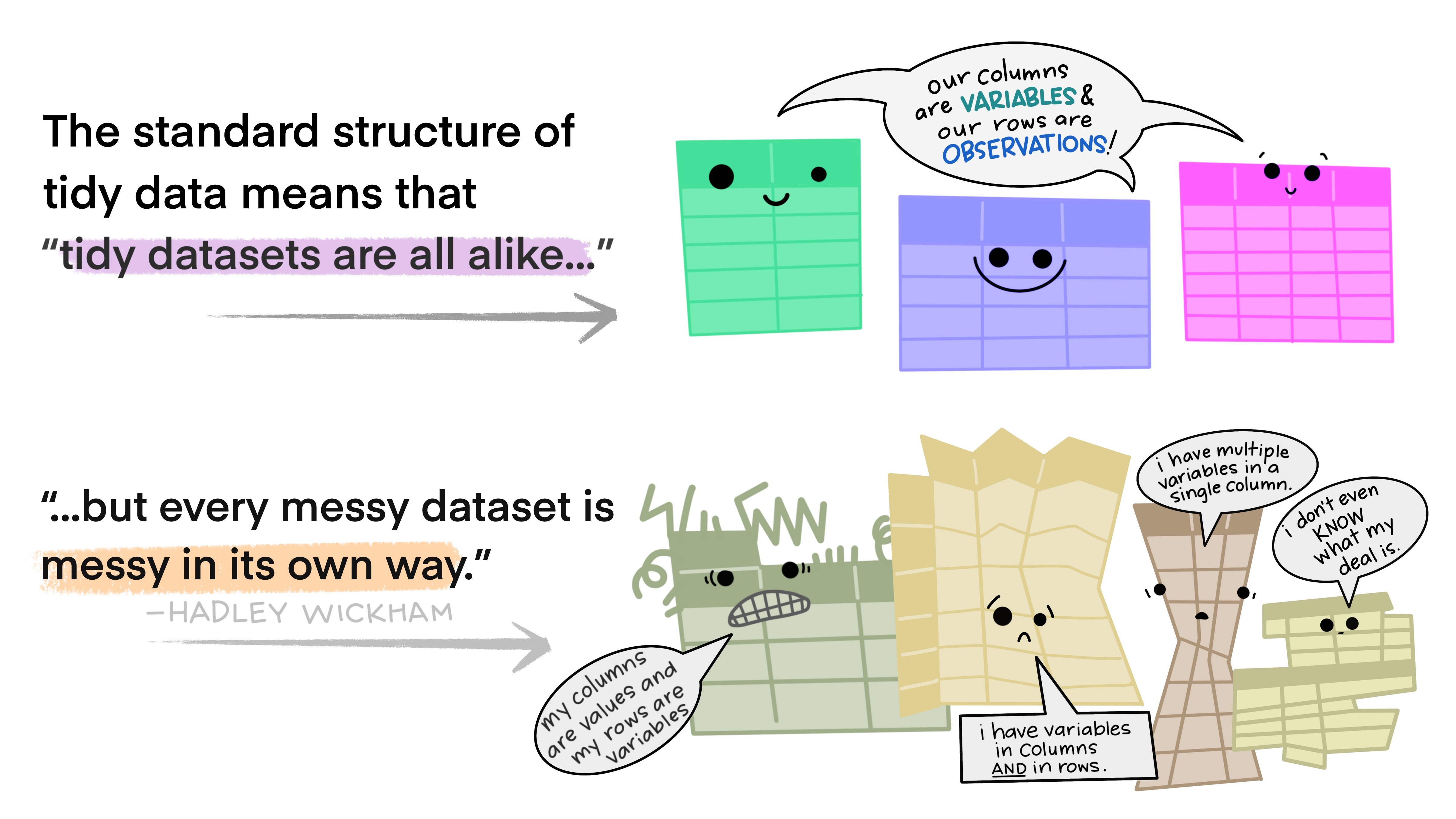
Tidy Data for future analyses and reproducibility
Joining Data from different Data Sources
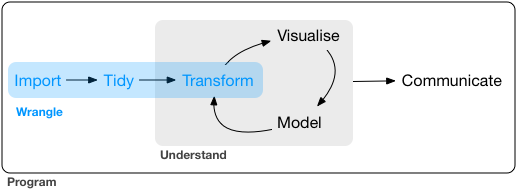
What is Data Wrangling?
Data wrangling can be defined as the process of cleaning, organizing, and transforming raw data into the desired format for analysts to use for prompt decision-making. Also known as data cleaning.
READING FILE TYPES - What file types can be read in with R? - Reading in different file types - Formatting your data: A tidy data discussion
(Review from Graphics Lecture)
DPLYR PACKAGE - filter, mutate, select, summarise, group by, and arrange
TIDYR PACKAGES - What is tidy data? - pivot longer, pivot wider and separate functions - lubridate package basics
JOINING DATASETS - Basic set theory logic (joining/combining datasets)